
Aprovechamiento de los aceleradores de hardware FIR e IIR en chip en un procesador de señal digital
Resumen
Los filtros de respuesta de impulso finito (FIR) y de respuesta de impulso infinito (IIR) son los algoritmos de procesamiento de señales digitales más utilizados, especialmente para aplicaciones de procesamiento de audio. Por lo tanto, una parte significativa del tiempo de un núcleo de procesador se consume para el filtrado FIR e IIR en un sistema de audio típico. Los aceleradores de hardware FIR e IIR en chip, también denominados FIRA e IIRA, respectivamente, en un procesador de señal digital se pueden usar para descargar las tareas de procesamiento FIR e IIR, liberando así el núcleo para otro procesamiento. En este artículo, discutiremos cómo hacer uso de estos aceleradores en la práctica con la ayuda de diferentes modelos de uso ilustrados con ejemplos probados en tiempo real.
Introducción

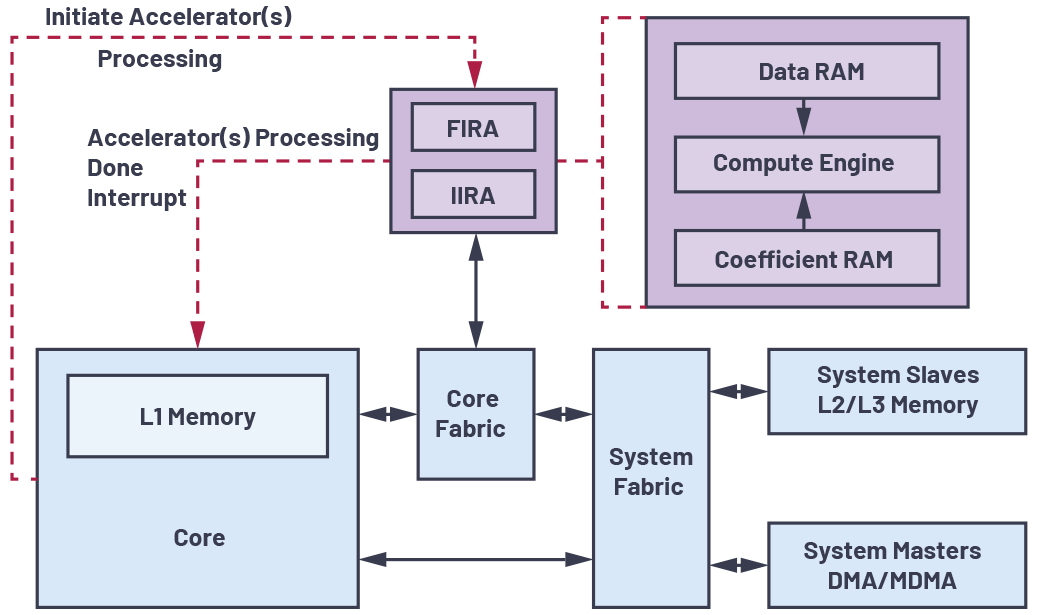
La Figura 1 muestra un diagrama de bloques simplificado de FIRA e IIRA y cómo interactúan con el resto del sistema y los recursos del procesador.
- Tanto los bloques FIRA como IIRA consisten principalmente en un motor de cómputo (unidades de multiplicación y acumulación (MAC)) junto con una pequeña memoria RAM local de datos y coeficientes.
- Para iniciar el procesamiento FIRA/IIRA, el núcleo inicializa una cadena de bloques de control de transferencia (TCB) DMA en la memoria del procesador con información específica del canal. Luego, el núcleo escribe el registro de puntero de cadena FIRA/IIRA con la dirección de inicio de esta cadena TCB y luego configura el registro de control FIRA/IIRA para iniciar el procesamiento del acelerador. Una vez que se completa el procesamiento de todos los canales, se envía una interrupción al núcleo para que pueda usar la salida procesada para otras operaciones.
- Teóricamente, el mejor enfoque es descargar todas las tareas de FIR y/o IIR del núcleo a los aceleradores y permitir que el núcleo haga otra cosa en paralelo. Pero en la práctica, esto puede no ser siempre factible, particularmente cuando el núcleo necesita usar la salida del acelerador(es) para un procesamiento posterior y no tiene otras tareas independientes para terminar en paralelo. En tales casos, debemos elegir el modelo de uso del acelerador apropiado para lograr los mejores resultados.
En este artículo, analizaremos varios modelos para usar estos aceleradores de manera óptima para diferentes escenarios de aplicación.
Uso de FIRA e IIRA en tiempo real


La figura 2 muestra un diagrama de flujo de datos de audio PCM en tiempo real típico. Un cuadro de datos de audio PCM digitalizados se recibe a través de un puerto serie síncrono (SPORT) y se envía a la memoria a través del acceso directo a la memoria (DMA). Mientras se lleva a cabo la recepción del cuadro N+1, el núcleo y/o los aceleradores procesan el cuadro N, y la salida del cuadro previamente procesado (N-1) se envía a través de SPORT al DAC para digitalización. conversión a analógico.
Modelos de uso del acelerador
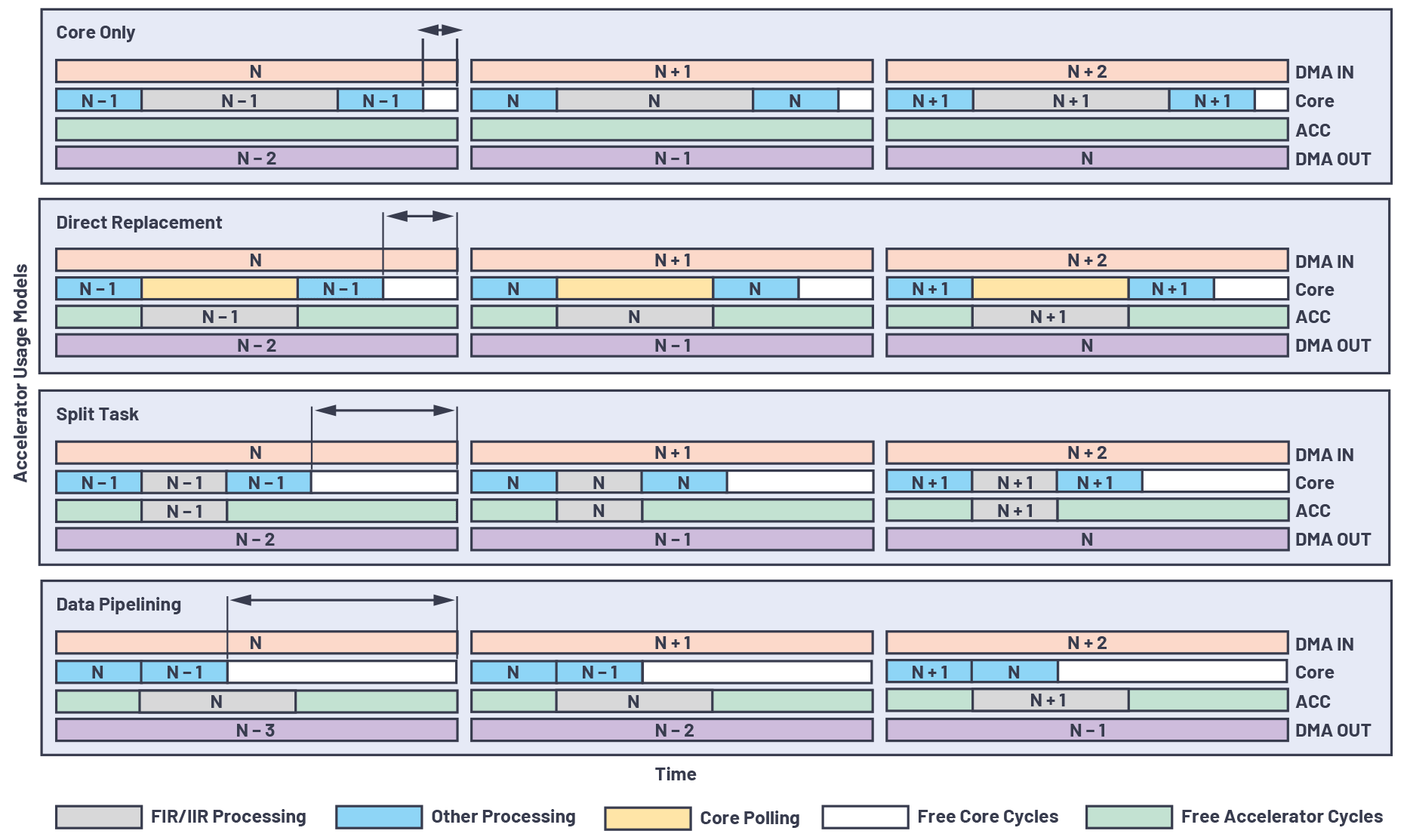
Como se discutió anteriormente, dependiendo de la aplicación, es posible que los aceleradores deban usarse de diferentes maneras para descargar el máximo de tareas de procesamiento FIR y/o IIR y para ahorrar la mayor cantidad posible de ciclos centrales para otras operaciones. En un nivel alto, los modelos de uso del acelerador se pueden dividir en tres categorías: reemplazo directo, tarea dividida y canalización de datos.
Reemplazo directo
- El procesamiento FIR y/o IIR del núcleo se reemplaza directamente por los aceleradores y el núcleo simplemente espera a que los aceleradores terminen el trabajo.
- Este modelo es efectivo solo cuando el acelerador puede procesar más rápido que el núcleo; es decir, usando el bloque FIRA.
Tarea dividida
- Las tareas de procesamiento de FIR y/o IIR se dividen entre el núcleo y el(los) acelerador(es).
- Este modelo es especialmente útil cuando hay múltiples canales disponibles para ser procesados en paralelo.
- Según una estimación de tiempo aproximada, el número total de canales se puede dividir entre el núcleo y el(los) acelerador(es) de tal manera que ambos terminen aproximadamente al mismo tiempo.
- Como se muestra en la Figura 3, este modelo de uso da como resultado más ahorros en el ciclo central que el reemplazo directo modelo.
Canalización de datos
- El flujo de datos entre el núcleo y los aceleradores se puede canalizar de tal manera que ambos puedan funcionar en paralelo en diferentes marcos de datos.
- Como se muestra en la Figura 3, el núcleo procesa el Nel marco y luego inicia el procesamiento del acelerador de este marco. Luego, el núcleo continúa en paralelo para procesar aún más el N-1el salida de cuadro producida por los aceleradores en la iteración anterior. Esta secuencia permite la descarga completa de la tarea de procesamiento FIR y/o IIR a los aceleradores a costa de una latencia de salida adicional.
- Las etapas de canalización y, en consecuencia, la latencia de salida pueden aumentar según el número de tales etapas de procesamiento FIR y/o IIR en la cadena de procesamiento completa.
La Figura 3 ilustra cómo fluyen los marcos de datos de audio entre tres etapas: DMA IN, procesamiento de núcleo/acelerador y DMA OUT, para varios modelos de uso del acelerador. También muestra cómo aumentan los ciclos de núcleo libre en comparación con el modelo de solo núcleo mediante la descarga total o parcial del procesamiento FIR/IIR al acelerador en diferentes modelos de uso del acelerador.

FIRA e IIRA en procesadores SHARC
Los siguientes dispositivos analógicos SHARC® Las familias de procesadores admiten FIRA e IIRA en chip (del más antiguo al más nuevo).
En todas las familias de procesadores:
- La velocidad de cálculo varía.
- El modelo de programación básico sigue siendo el mismo excepto por el modo de configuración automática (ACM) en los procesadores ADSP-2156x.
- FIRA tiene cuatro unidades MAC mientras que IIRA tiene una sola unidad MAC.
Mejoras de FIRA/IIRA en los procesadores ADSP-2156x
ADSP-2156x es la última incorporación a la familia de procesadores SHARC. Es el primer procesador SHARC de un solo núcleo de 1 GHz con FIRA e IIRA también capaz de funcionar a 1 GHz. FIRA e IIRA en los procesadores ADSP-2156x ofrecen varias mejoras con respecto a sus predecesores, los procesadores ADSP-SC58x/ADSP-SC57x.
Mejoras de rendimiento
- La velocidad de cómputo aumentó ocho veces (SCLK-125 MHz a CCLK-1 GHz).
- Es posible una menor latencia de acceso a datos y MMR entre el núcleo y los aceleradores debido a una integración más estrecha del núcleo y los aceleradores con la ayuda de una estructura central dedicada.
Mejoras funcionales
Se agregó soporte para ACM para minimizar la intervención central requerida para manejar el procesamiento del acelerador. Este modo viene con las siguientes características principales nuevas:
- Permite detener el acelerador para la cola de tareas dinámicas.
- Sin limitación de número de canales.
- Compatibilidad con la generación de disparadores (maestro) y la espera de disparadores (esclavo).
- Generación selectiva de interrupciones para cada canal.
Resultados experimentales
En esta sección, analizaremos los resultados de dos casos de uso de FIR/IIR multicanal en tiempo real implementados con la ayuda de diferentes modelos de uso de aceleradores en una placa de evaluación ADSP-2156x.
Caso de uso 1
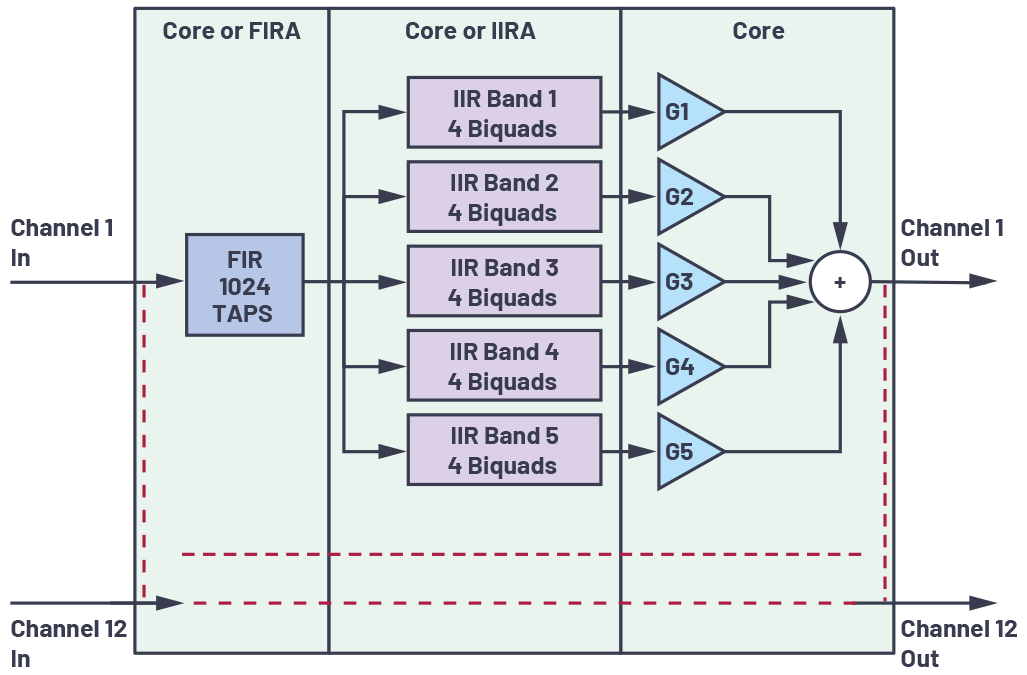
La figura 4 muestra el diagrama de bloques del caso de uso 1. La frecuencia de muestreo es de 48 kHz, el tamaño del bloque es de 256 muestras y la proporción de canales de núcleo a acelerador utilizados en el modelo de tareas divididas es de 5:7.
La Tabla 1 muestra los números de FIRA MIPS y de núcleo medidos junto con los ahorros de MIPS de núcleo resultantes en comparación con el modelo de solo núcleo. La tabla también muestra la latencia de salida adicional agregada por el modelo de uso correspondiente. Como podemos ver, con el uso del acelerador, se podrían guardar hasta 335 MIPS centrales con un modelo de uso de canalización de datos, al costo de 1 bloque (5,33 ms) de latencia de salida. Reemplazo directo y tarea dividida Los modelos de uso también dan como resultado ahorros de 98 MIPS y 189 MIPS, respectivamente, sin ninguna latencia de salida adicional.

| Modelo de uso | Núcleo MIPS | FIRA MIPS | IIRA MIPS | Ahorro de Core MIPS | Modelo de uso Latencia (ms) |
| Solo núcleo | 337 | 0 | |||
| Reemplazo directo | 239 | 162 | 75 | 98 | 0 |
| Tarea dividida | 148 | 96 | 44 | 189 | 0 |
| Canalización de datos | 2 | 161 | 75 | 335 | 5.33 (1 cuadro) |
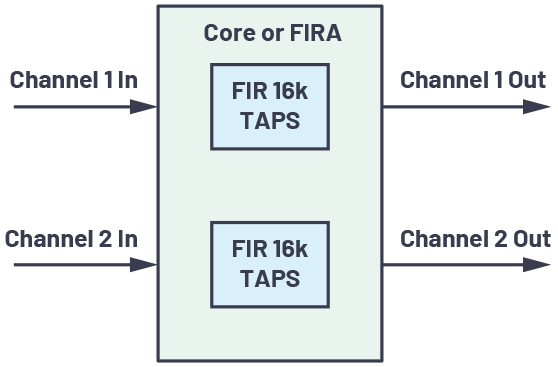
Caso de uso 2
La Figura 5 muestra el diagrama de bloques del caso de uso 2. La frecuencia de muestreo es de 48 kHz, el tamaño del bloque es de 128 muestras y la proporción de canales de núcleo a acelerador utilizados en el modelo de tareas divididas es 1:1.
Al igual que la Tabla 1, la Tabla 2 muestra los resultados para este caso de uso. Como podemos ver, con el uso del acelerador, se podrían guardar hasta 490 MIPS centrales con un modelo de uso de canalización de datos al costo de 1 bloque (2,67 ms) de latencia de salida. Un modelo de uso de tareas divididas da como resultado un ahorro de 234 MIPS centrales sin ninguna latencia de salida adicional. Tenga en cuenta que, a diferencia del caso de uso 1, el procesamiento en el dominio de la frecuencia (convolución rápida) se usa para el núcleo en lugar del procesamiento en el dominio del tiempo. Esta es la razón por la cual el núcleo MIPS tomado para procesar un canal es menor que el FIRA MIPS tomado, lo que resulta en ahorros negativos de núcleo MIPS para el modelo de uso de reemplazo directo.

| Modelo de uso | Núcleo MIPS | FIRA MIPS | Ahorro de Core MIPS | Modelo de uso Latencia (ms) |
| Solo núcleo | 493 | 0 | ||
| Reemplazo directo | 515 | 511 | –22 | 0 |
| Tarea dividida | 259 | 257 | 234 | 0 |
| Canalización de datos | 3 | 511 | 490 | 2,67 (1 cuadro) |
Conclusión
En este artículo, hemos visto cómo se pueden descargar MIPS centrales significativos a los aceleradores FIRA e IIRA en los procesadores ADSP-2156x, utilizando diferentes modelos de uso del acelerador para lograr los perfiles de procesamiento y MIPS deseados.
Otras lecturas
“Demostración gráfica del rendimiento y uso en tiempo real del acelerador ADSP-2156x FIR/IIR.” dispositivos analógicos, inc.
Nayak, Sanket y Mitesh Moonat. “Nota de ingeniero a ingeniero EE-408: uso de aceleradores FIR/IIR de alto rendimiento ADSP-2156x”. Dispositivos analógicos, Inc., agosto de 2019.
Si quieres conocer otros artículos parecidos a Aprovechamiento de los aceleradores de hardware FIR e IIR en chip en un procesador de señal digital puedes visitar la categoría Generalidades.
Deja una respuesta
¡Más Contenido!